前言
这是论文系列的第一篇文章,为什么选择它呢?在2017年这篇文章发布之初其影响力还局限在NLP机器翻译这一小众领域,彼时鲜有人能想到它会在短短几年内席卷整个行业,甚至成为连接CV与NLP这两个长期割裂江湖的桥梁,几于开创了一个全新的AI时代!七载光阴,诸如GTP、Stable Diffusion、Sora等一系列上层建筑的不断涌现足以证明它的不朽,值此文七周年之际,我谨怀热诚重新拜读,并将之作为建站以来的第一篇精读文章,除了致敬之意也是希望能以此激励己身,饮冰十年,难凉热血,愿来时再回首,当时明月依旧。
正文
本文仅针对论文中提出的关键概念及开创性方法进行展开,并非全文翻译哦!文中所述仅是我的个人理解,学识浅薄,有偏差之处还请小伙伴们不吝指正,在此拜谢。
摘要
当前用于序列转录的模型多是Encoder-Decoder结构的RNN或者CNN,其中使用了注意力模块的模型表现突出。然而RNN的结构决定了它难以并行化训练,计算开销大而CNN对较长的时序信息难以进行建模,需要多个卷积层进行堆叠。因此作者基于Encoder-Decoder架构提出了一种完全依赖注意力机制的Transformer模型,其可以并行化训练,且使用多头注意力机制替代RNN中的循环层来识别不同的模式从而达到CNN中多通道输出的效果。实验表明,Transformer不仅在机器翻译任务上表现良好还可以很好的泛化至其他音视频任务。
当然,Transformer并非全能,虽然可以并行处理,但是长序列而言,注意力机制是计算密集型的,对资源的要求较高,由于参数量较大,Transformer适合大量数据的训练,其在小数据集上容易过拟合。
模型结构
由于模型整体结构组成比较复杂,为了保证内容的连贯性及易于理解,此处我采用逐模块顺序分解的方式进行介绍,模型总体结构如图所示
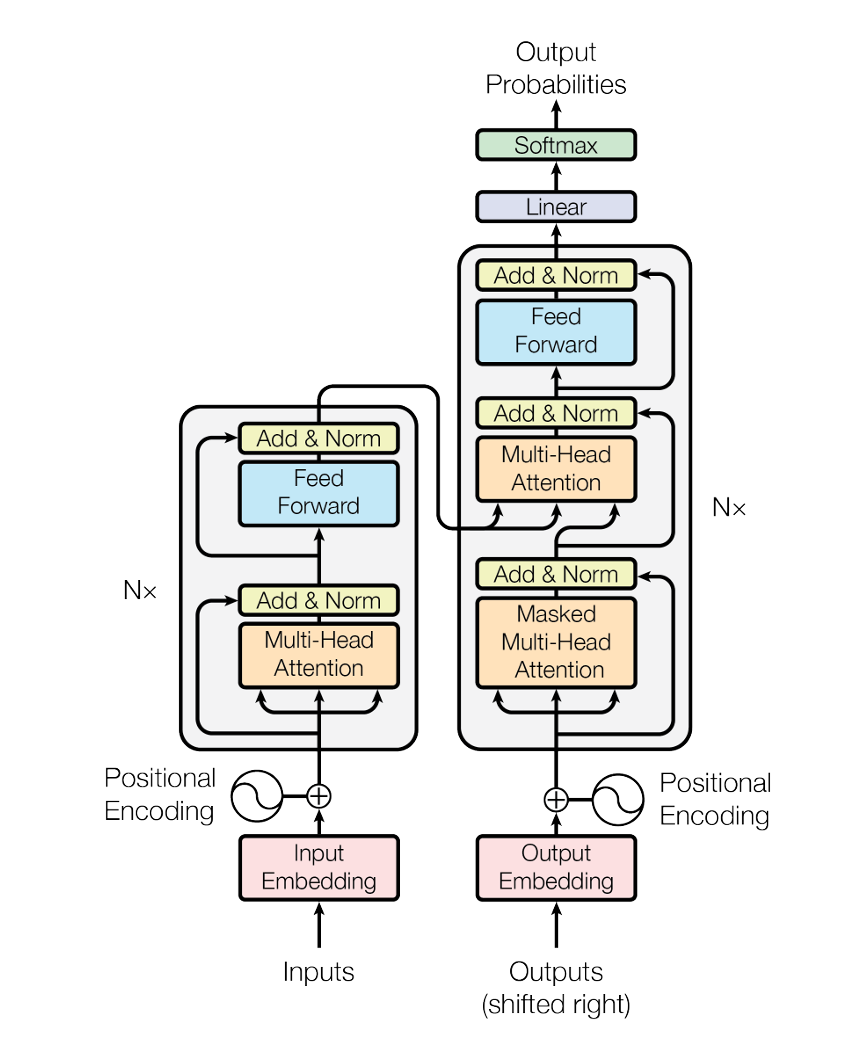
Input/Output Embedding
Embedding在NLP中主要指的是词嵌入操作,如果是第一次接触NLP领域的小伙伴可能不太理解,一个直观的解释是词嵌入操作就是将我们真实输入的一句话中的单元也称为token(在英文中体现可以是单词本身,也可以是词根等)映射到一个特殊的语义空间,也称为潜空间或隐空间,即用一个高维向量表达token,在这个高维抽象空间中世界上的各种语言文字没有书写形式、发音等结构化的区别,只表现出纯粹的语义信息。
在Transformer中Embedding操作主要被用在编码器输入、解码器输入以及解码器输出三个位置,用于将真实输入的句子转化为潜空间中的语义向量以及将语义向量再转回目标语言从而输出token。
Positional Encoding
由于后面的注意力模块本质上仅仅是对输入的语义向量进行加权求和操作,其中是不含时序信息的,换句话说交换输入中两个单词的顺序,可能句子的意思就完全不同了,例如去上海和去海上,但是注意力却不能获取这种时序信息,至多导致输出向量的位置不同。因此这里Transformer使用了位置编码(Positional Encoding),将单词的位置信息加入到词Embedding后的语义向量中,从而获得类似RNN的语句时序信息。
这里Transformer使用的位置编码是通过加法形式作用的,即将每个词的位置下标(1、2、3、4·····)投射到一个与Embedding语义向量相同维度的空间中,再将词向量矩阵与位置编码向量相加即可。那么如何把自然数位置投射到一个高维向量空间中呢,文中给出的公式如下:
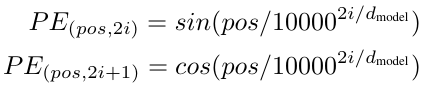
其中pos指的就是单词所处的位置下标,i指的是映射后向量的列标(即维度),$d_{model}$指的是Embedding后每个词的表示维度。
遗憾的是,在论文中并未被对上述公式的推导和来源做出解释,但通过观察公式给我的直观感觉就是奇偶项交替及sin/cos交替,这样的特征很容易联想到傅里叶级数,由于本文重点不在此处,就不再赘述,在文末附上关于位置编码的详细解读供大家参考。
Multi-Head Attention
概念
俗话说攘外必先安内,想要理解多头注意力,就必先了解什么是注意力。当然,注意力有很多种,在Transformer里我们使用的是QKV注意力,论文中的解释如下
注意力函数可以描述为将一个查询(Query)和一组键-值(Key-Value)对映射到一个输出,其中查询、键、值和输出都是向量。输出被计算为值的加权和,其中分配给每个值的权重由查询与相应键的相似度函数计算得到。简单梳理下,这里说输出是值的加权和,换句话说一个Query的输出其维度应该与Value是相同的,是每个Value乘以权重再相加的结果,那么这里的权重从何而来?其实是Query向量和Key向量进行相似度函数计算的结果,相似度函数有很多种,不同的相似度函数导致了不同的注意力名称,在这里Transformer采用的是名为Scaled Dot-Product Attention的注意力,顾名思义它的相似度计算方法就是简单的将两个向量进行点乘也就是做内积操作,那么自然当得出的值越大就意味着两个向量相似度越高,一个Query与n个Key逐一进行内积最终会得出n个值,再将这n个值进行softmax操作后就转化为了与n个非负且和为1的权重,也就是最终与Value相乘的权重,那么名称Scaled Dot-Product Attention中的Scaled体现在哪里呢?其实在进行softmax前所有内积值还需要除以$\sqrt{d_{k}}$,这里dk指的是Key向量的维度,其原因主要是考虑到dk维度过大的情况下可能导致部分内积也很大或很小,从而经过softmax后的部分值极度偏向于0或1,导致在计算时梯度较小影响训练效率。最终的公式组成和计算图如下
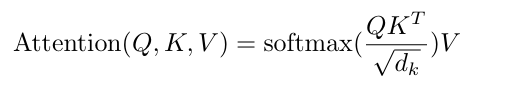
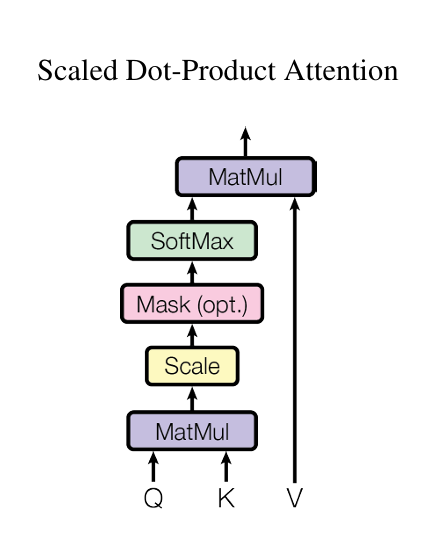
嗯?计算图中这个粉红色Mask是啥捏,注意到后面括号中的opt. 代表它是一个可选操作,其实在编码器的多头注意力模块中并不需要它而其主要是用于解码器中的多头注意力模块,它的功能简单来说就是让t时刻的查询$Q_t$只对$K1···K{t-1}$计算权重而不考虑t时刻之后的Key,具体做法是在softmax操作前将t时刻及后续时刻的内积值替换为一个非常大的负数,那么自然在softmax操作时这些时刻的权重就会趋于0。换句话说在执行翻译任务的时候模型只能依靠之前的翻译结果而不能窥见未来。
OK,介绍完注意力,再回到上层建筑——Multi-Head Attention。简单来说,它的主要操作是把输入的QKV向量通过线性层投影到一个较低的维度,并在这个低维QKV向量上执行注意力计算,并且重复操作h次,再将这h次的结果进行concat拼接最后通过一个线性层回到原始维度。其公式及计算图如下

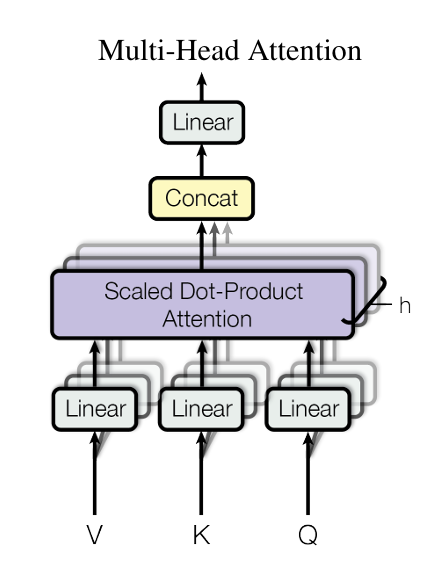
那么为什么要使用这种多头结构呢?不知道大家是否注意到上述的Scaled Dot-Product Attention中其实是没有任何可学习参数的——仅仅做了内积和softmax运算,而这里的多头注意力模块引入了线性层使得模型可以学习不同的投影模式来拟合各自的相似度函数,就如同在CNN当中用多个卷积核来提取不同类型的特征。
什么叫做不同的投影方式呢?这里举一个我在查阅相关资料时发现的例子来帮助大家理解。
考察这样一个句子
The animal didn’t cross the street, because it was too tired.在单头注意力和多头注意力的情况下可视化结果如下

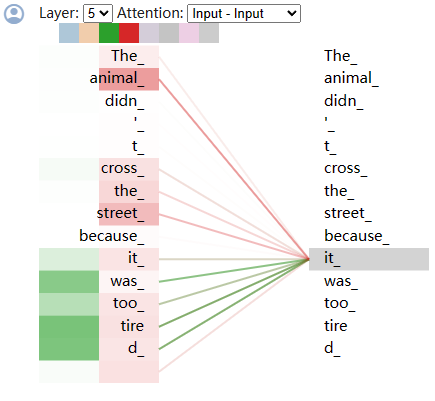
位于上侧的图片是单头注意力的情况,可以看出此处粉线表示的注意力主要反映了it在指代层面的语义信息,即在句子中it指代animal。而在下侧的多头注意力情况中,新加入的绿线注意力权重集中在tired等表示状态的词上,可以认为此处绿线注意力主要反映it在状态层面的语义信息。换句话说,多头注意力可以简单理解为在不同层面或者说角度上表达出的词语的关联程度,每个注意力头都有自己的一套关联规则。当然这个例子只是为了方便理解,在实际情况下往往很难通过人为分析出每个注意力头的映射规律。例如上面的例子如果加入全部的八个注意力头的话,可视化是酱紫的:

是不是难以解读了?以上可视化案例可以通过Tensor2Tensor notebook访问,大家感兴趣的话不妨自己尝试一下。
其实,不知道大家发现没有,这里注意力机制的计算量并没有因为引入了多头而明显增大,总的来说,计算复杂度还是与序列长度的平方成正比,这也意味着随着序列长度的增加,其计算成本增长很快,所以GPT都会对token/context长度进行限制 (gpt-4和gpt-4-32k的limit分别是8192和32768而chatGPT是4096,这可能也是GPT4.0性能好但响应速度比ChatGPT慢的原因吧)。
至此,Multi-Head Attention的主要概念介绍完毕。
代码
虽然在论文中多头注意力是通过多个线性层进行维度上的压缩操作,但其实通过矩阵运算可以很轻松的实现八个注意力头的并行运算。下面给出多头注意力模块的具体实现,参照各行注释应该可以帮助大家快速理解。
import numpy as np
import torch
from torch import nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_head, dropout_prob=0.1):
super().__init__()
# d_model即embedding后的词向量维数
self.d_model = d_model
# d_k即每个头的词向量维数
self.d_k = d_model // num_head
# d_v即注意力输出的词向量维数,论文中d_q=d_v=d_k=d_model/num_head
self.d_v = self.d_k
# 注意力头数
self.num_head = num_head
# 概率丢弃
self.dropout = nn.Dropout(dropout_prob)
# QKV三个线性变换矩阵
self.WQ = nn.Linear(d_model, num_head * self.d_k)
self.WK = nn.Linear(d_model, num_head * self.d_k)
self.WV = nn.Linear(d_model, num_head * self.d_v)
# 输出维度校正
self.WOUT = nn.Linear(num_head * self.d_v, d_model)
def forward(self, query, key, value, mask=None):
# 输入QKV维度均为[batch_size,seq_len,d_model]
batch_size, seq_len, d_model = query.shape
# 将QKV向量按头数进行拆分及变形
# [batch_size,seq_len,d_model]->[batch_size,seq_len,num_head,d_k]->[batch_size,num_head,seq_len,d_k]
Query = self.WQ(query).view(batch_size, seq_len, self.num_head, self.d_k).permute(0, 2, 1, 3)
Key = self.WK(key).view(batch_size, seq_len, self.num_head, self.d_k).permute(0, 2, 1, 3)
Value = self.WV(value).view(batch_size, seq_len, self.num_head, self.d_v).permute(0, 2, 1, 3)
# 计算相似度得分attn_scores
# Q:[batch_size,num_head,seq_len,d_k]×K转置:[batch_size,num_head,d_k,seq_len]
# 高维矩阵乘法只对最后两个维度进行计算
# attn_scores:[batch_size,num_head,seq_len,seq_len]
attn_scores = torch.matmul(Query, Key.transpose(-1, -2)) / np.sqrt(self.d_k)
# 应用注意力掩码
if mask is not None:
# 此处mask:[batch_size,seq_len,seq_len]
assert mask.size() == (batch_size, seq_len, seq_len)
# 在第二维度前增加一个维度——头数维度,并通过repeat函数重复num_head次,使得掩码张量在头维度上进行广播以便与多头注意力机制中的多个头对应。
mask = mask.unsqueeze(1).repeat(1, self.num_head, 1, 1)
# 将处理后的张量转换为布尔类型,以便后续在计算中使用掩码进行元素级别的操作。
mask = mask.bool()
# 使用masked_fill_函数在保持张量形状不变的情况下,将掩码位置的值替换为指定的填充值即一个足够小的负数
attn_scores.masked_fill_(mask, -1e5)
# 对最后一维进行softmax操作,得到attn_weight即注意力权重
attn_weight = torch.softmax(attn_scores, dim=-1)
# 对权重进行dropout正则操作,降低过拟合风险
attn_weight = self.dropout(attn_weight)
# 将得到的权重与Value相乘得到输出即加权和
output = torch.matmul(attn_weight, Value)
# 多头注意力合并
# output:[batch_size, num_head, seq_len, d_v]->[batch_size, seq_len, num_head, d_v]
# contiguous()将维度置换后的张量存储空间改为连续存储
# view对最后的d_v维度进行堆叠,完成论文中的concat操作
output = output.permute(0, 2, 1, 3).contiguous().view(batch_size, seq_len, self.d_v * self.num_head)
# 最后通过输出线性层,将维度修正为d_model
# output:[batch_size, seq_len, d_model]
output = self.WOUT(output)
return output
if __name__ == '__main__':
batch_size = 4
seq_len = 5
d_model = 512
num_head = 8
attn_mask = torch.rand(batch_size, seq_len, seq_len)
# 创建MultiHeadAttention实例
multihead_attn = MultiHeadAttention(d_model=d_model, num_head=num_head)
# 生成模拟的输入张量
Q = torch.rand(batch_size, seq_len, d_model)
K = torch.rand(batch_size, seq_len, d_model)
V = torch.rand(batch_size, seq_len, d_model)
# 调用forward方法计算多头注意力输出
output = multihead_attn(Q, K, V, attn_mask)
print(output.shape)
# [4,5,512]Pytorch代码实现
Encoder
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_head, d_ffn, drop_prob=0.1):
"""
Args:
d_model: 词向量语义特征维度
num_head: 注意力头数
d_ffn: 逐位置前馈网络隐层维度即隐藏单元数量
drop_prob: 丢弃概率
"""
# 确保特征维数可被头数整除,这样多头注意力在最后拼接时可以还原成原始的特征维数
assert d_model % num_head == 0
super(EncoderLayer, self).__init__()
# LayerNorm
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
# MultiHeadAttention
self.multi_head_attn = MultiHeadAttention(d_model=d_model, num_head=num_head, drop_prob=drop_prob)
# Position-wise Feedforward Neural Network
self.poswise_ffn = PositionwiseFeedForwardNetwork(d_model=d_model, d_ffn=d_ffn, drop_prob=drop_prob)
def forward(self, enc_in, enc_len_mask):
"""
Args:
enc_in: [batch, max_src_len, d_model],解码器输入
enc_len_mask: [batch, max_src_len, max_src_len],掩码矩阵,用于对长度不足max_src_len的输入序列padding部分进行屏蔽,防止padding部分对注意力分数计算产生影响
"""
# 此处residual用于保留多头注意力模块残差连接的原始输入,残差连接的概念来源于ResNet,此处不再赘述
residual = enc_in
# MultiHeadAttention
# 由于此处为自注意力,Q/K/V输入相同都是enc_in
context = self.multi_head_attn(enc_in, enc_in, enc_in, enc_len_mask)
# 残差连接及正则
out = self.norm1(residual + context)
# 此处residual用于保留逐位置前馈网络模块残差连接的原始输入
residual = out
# position-wise feedforward
out = self.poswise_ffn(out)
# 残差连接及正则
out = self.norm2(residual + out)
# out:[batch, max_src_len, d_model]
return out
class Encoder(nn.Module):
def __init__(self, d_model, d_ffn, num_head, num_layer, drop_prob, src_vacab_size, max_src_len):
"""
Args:
d_model: 词向量语义特征维度
d_ffn: 逐位置前馈网络隐层维度即隐藏单元数量
num_head: 注意力头数
num_layer: 编码器堆叠层数
drop_prob: 丢弃概率
src_vacab_size: 源词库大小,用于对原始输入进行词嵌入操作
max_src_len: 最大源序列长度
"""
super(Encoder, self).__init__()
# 输入embedding
self.src_emb = nn.Embedding(src_vacab_size, d_model)
# 位置embedding,此处使用论文中预定义的正余弦位置编码函数,freeze=True表示位置编码固定不变,此处也可以使用类似src_emb的可学习参数的位置编码
self.pos_emb = nn.Embedding.from_pretrained(pos_sinusoid_embedding(max_src_len, d_model), freeze=True)
# dropout正则层
self.dropout_emb = nn.Dropout(drop_prob)
# 此处ModuleList用于定义后续EncoderLayer的多层堆叠
self.layers = nn.ModuleList([
EncoderLayer(d_model, num_head, d_ffn, drop_prob) for _ in range(num_layer)
])
def forward(self, X, mask=None):
"""
Args:
X: [batch, max_src_len],编码器源输入即源词库的索引
类似[[1,5,8],[7,5,3]]表示batch大小为2,其中第一行[1,5,8]表示一个句子每个单词在词库中的索引,如vocab[1]='I', vocab[5]='love', vocab[8]='you'
mask: [batch, max_src_len, max_src_len],掩码矩阵,用于对长度不足max_src_len的输入序列padding部分进行屏蔽,防止padding部分对注意力分数计算产生影响
"""
# src_embedding:[batch,max_src_len,d_model],简而言之src_emb将输入的每个序列的每个词索引转化为了隐空间中d_model维的语义向量
src_embedding = self.src_emb(X)
# pos_embedding:[batch,max_src_len,d_model],同理pos_emb将输入的每个序列的每个词的位置转化为了隐空间中d_model维的语义向量
pos_embedding = self.pos_emb(torch.arange(X.shape[1], device=X.device))
# enc_out:[batch,max_src_len,d_model],将两个嵌入层按位相加
enc_out = self.dropout_emb(src_embedding + pos_embedding)
# 循环堆叠EncoderLayer层,每一层的输出作为下一层的输入,在论文中此处堆叠层数N=6
for layer in self.layers:
enc_out = layer(enc_out, mask)
return enc_outDecoder
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_head, d_ffn, drop_prob=0.1):
"""
Args:
d_model: 词向量语义特征维度
num_head: 注意力头数
d_ffn: 逐位置前馈网络隐层维度即隐藏单元数量
drop_prob: 丢弃概率
"""
super(DecoderLayer, self).__init__()
assert d_model % num_head == 0
# LayerNorms
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
# Position-wise Feed-Forward Networks
self.poswise_ffn = PositionwiseFeedForwardNetwork(d_model, d_ffn, drop_prob)
# 解码器自注意力模块
self.dec_attn = MultiHeadAttention(d_model, num_head, drop_prob)
# 编码器-解码器交叉注意力模块
self.enc_dec_attn = MultiHeadAttention(d_model, num_head, drop_prob)
def forward(self, dec_in, enc_out, dec_mask, dec_enc_mask):
# 此处residual用于保存解码器自注意力模块残差连接的原始输入
residual = dec_in
# 自注意力模块 forward
context = self.dec_attn(dec_in, dec_in, dec_in, dec_mask)
# 残差连接及正则
dec_out = self.norm1(residual + context)
# 此处residual用于保存编解码交叉注意力模块残差连接的原始输入
residual = dec_out
# 交叉注意力模块 forward
context = self.enc_dec_attn(dec_out, enc_out, enc_out, dec_enc_mask)
# 残差连接及正则
dec_out = self.norm2(residual + context)
# 此处residual用于保存逐位置前馈网络模块残差连接的原始输入
residual = dec_out
# 逐位置前馈网络 forward
out = self.poswise_ffn(dec_out)
# 残差连接及正则
dec_out = self.norm3(residual + out)
# decout:[batch, tgt_len, d_model]
return dec_out
class Decoder(nn.Module):
def __init__(
self, d_model, d_ffn, num_head, num_layer, drop_prob, tgt_vocab_size, max_tgt_len):
"""
Args:
d_model: 词向量语义特征维度
d_ffn: 逐位置前馈网络隐层维度即隐藏单元数量
num_head: 注意力头数
num_layer: 编码器解码器堆叠层数
drop_prob: 丢弃概率
tgt_vocab_size: 目标词库大小
max_tgt_len: 最大目标序列长度,同时也是模型输出序列的最大值
"""
super(Decoder, self).__init__()
# 解码器输入词嵌入,由于是训练过程此处实际上是对标签序列进行嵌入操作,而在推理过程中则是对解码器上一时刻输出进行嵌入操作
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
# embedding dropout,同编码器
self.dropout_emb = nn.Dropout(drop_prob)
# position embedding,同编码器
self.pos_emb = nn.Embedding.from_pretrained(pos_sinusoid_embedding(max_tgt_len, d_model), freeze=True)
# decoder layers,同编码器,用于定义后续DecoderLayer的堆叠
self.layers = nn.ModuleList([
DecoderLayer(d_model, num_head, d_ffn, drop_prob) for _ in range(num_layer)
])
def forward(self, labels, enc_out, dec_subsequent_mask, dec_enc_mask):
"""
Args:
labels: [batch, max_tgt_len],标签序列即目标输出序列,为了加速模型收敛训练过程采用教师强制(Teacher Forcing)方法,即直接将标签作为解码器输入再结合掩码机制无需模型自己拟合
enc_out: [batch, max_src_len, d_model],编码器输出
dec_subsequent_mask: [batch, num_head, max_tgt_len, max_tgt_len],解码器时间步掩码,保证模型在t时刻只能看到t-1时刻及之前的输出,体现在注意力计算层面,我个人理解是t时刻的词只与t-1及之前的词计算注意力权重,而序列中的最后一个词则可以"看到"整句话除了自己之外的所有词并计算与它们之间的加权和
dec_enc_mask: [batch, num_head, max_tgt_len, max_src_len],编码器解码器交叉注意力掩码
"""
# label embedding and position embedding,同编码器
tgt_emb = self.tgt_emb(labels)
pos_emb = self.pos_emb(torch.arange(labels.size(1), device=labels.device))
dec_out = self.dropout_emb(tgt_emb + pos_emb)
# 循环堆叠DecoderLayer层,每一层的输出作为下一层的输入,在论文中此处堆叠层数N=6
for layer in self.layers:
dec_out = layer(dec_out, enc_out, dec_subsequent_mask, dec_enc_mask)
return dec_outTransformer
class Transformer(nn.Module):
def __init__(self, d_model, d_ffn, num_head, num_layer, drop_prob, src_vocab_size, max_src_len, tgt_vocab_size,
max_tgt_len) -> None:
"""
Args:
d_model: 词向量语义特征维度
d_ffn: 逐位置前馈网络隐层维度即隐藏单元数量
num_head: 注意力头数
num_layer: 编码器解码器堆叠层数
drop_prob: 丢弃概率
src_vocab_size: 源词库大小
max_src_len: 最大源序列长度,同时也是模型处理上下文的最大值
tgt_vocab_size: 目标词库大小
max_tgt_len: 最大目标序列长度,同时也是模型输出序列的最大值
"""
super().__init__()
# 初始化编码器类
self.encoder = Encoder(d_model, d_ffn, num_head, num_layer, drop_prob, src_vocab_size, max_src_len)
# 初始化解码器类
self.decoder = Decoder(d_model, d_ffn, num_head, num_layer, drop_prob, tgt_vocab_size, max_tgt_len)
# 用于将解码器输出维度映射至目标词库维度,方便后续利用softmax计算每个词的概率
self.linear = nn.Linear(d_model, tgt_vocab_size)
def forward(self, X: torch.Tensor, X_lens: torch.Tensor, labels: torch.Tensor):
"""
Args:
X: 模型的源输入 [batch_size, max_src_len]
X_lens: 模型源输入的每个句子的序列长度 [batch_size]
labels: 模型的目标输出标签用于计算模型损失,在训练过程中也同时作为解码器的输入 [batch_size, max_tgt_len]
"""
X_lens, labels = X_lens.long(), labels.long()
batch_size = X.size(0)
device = X.device
max_label_len = labels.size(1)
# 获取编码器序列长度掩码
enc_mask = get_len_mask(batch_size, d_model, X_lens, device)
# 执行编码器前向传播
enc_out = self.encoder(X, enc_mask)
# 获取解码器时间步掩码,防止模型在t时刻看到当前及未来的输出
dec_subsequent_mask = get_subsequent_mask(batch_size, max_label_len, device)
# 获取编码器解码器交叉注意力掩码
dec_enc_mask = get_enc_dec_mask(batch_size, d_model, X_lens, max_label_len, device)
# 执行解码器前向传播
dec_out = self.decoder(labels, enc_out, dec_subsequent_mask, dec_enc_mask)
# 将解码器结果映射至目标词库维度
logits = self.linear(dec_out)
return logits