截至2025年2月,偶然再次点进了阿里云社区的那个问题讨论贴,发现在24年下半年阿里云似乎把默认交换区大小从0改到了1024MB,虽然仍有使用者反馈swap 1024MB还是会发生宕机继续加大至4G方可,但也算终于有人发现了问题的本质解决方案之一 ( •̀ ω •́ )✧
前言
自博客初步搭建完成以后,写博文时大有一种居于云岫,光风霁月的畅快通达~,按照惯常剧本接下来当然是写文证道啦,奈何服务器突然接二连三莫名其妙的连续宕机,不得不说有点命途多舛的感觉~
吐槽结束,正片开始,事情是这样的,因为春节在家事务繁多没有过多关注网站运行情况,直到年后心血来潮试图通过域名回到前些天搭的赛博家乡,才发现迎接我的只有无止尽的加载错误,b站百度一路畅通,但Xshell却始终无法连接,不祥的预感油然而生,马上登录阿里云控制台试图通过Workbench和VNC连接,喜提失败x2,打开监控页面才发现CPU早在几个小时前就已经处于满载,在短短一分钟内CPU利用率从1%飙升至90%+,云盘读写也在完全没有进行任何外力干预下逼近阈值,再尝试访问部署的其他服务时也毫无意外的全部宕机了······
而这样突然的宕机犹如陷入死锁,唯一的解决办法就是强制重启,且在后续的几天几乎每隔一天就会出现,时至今日整体的资源视图大致如下:
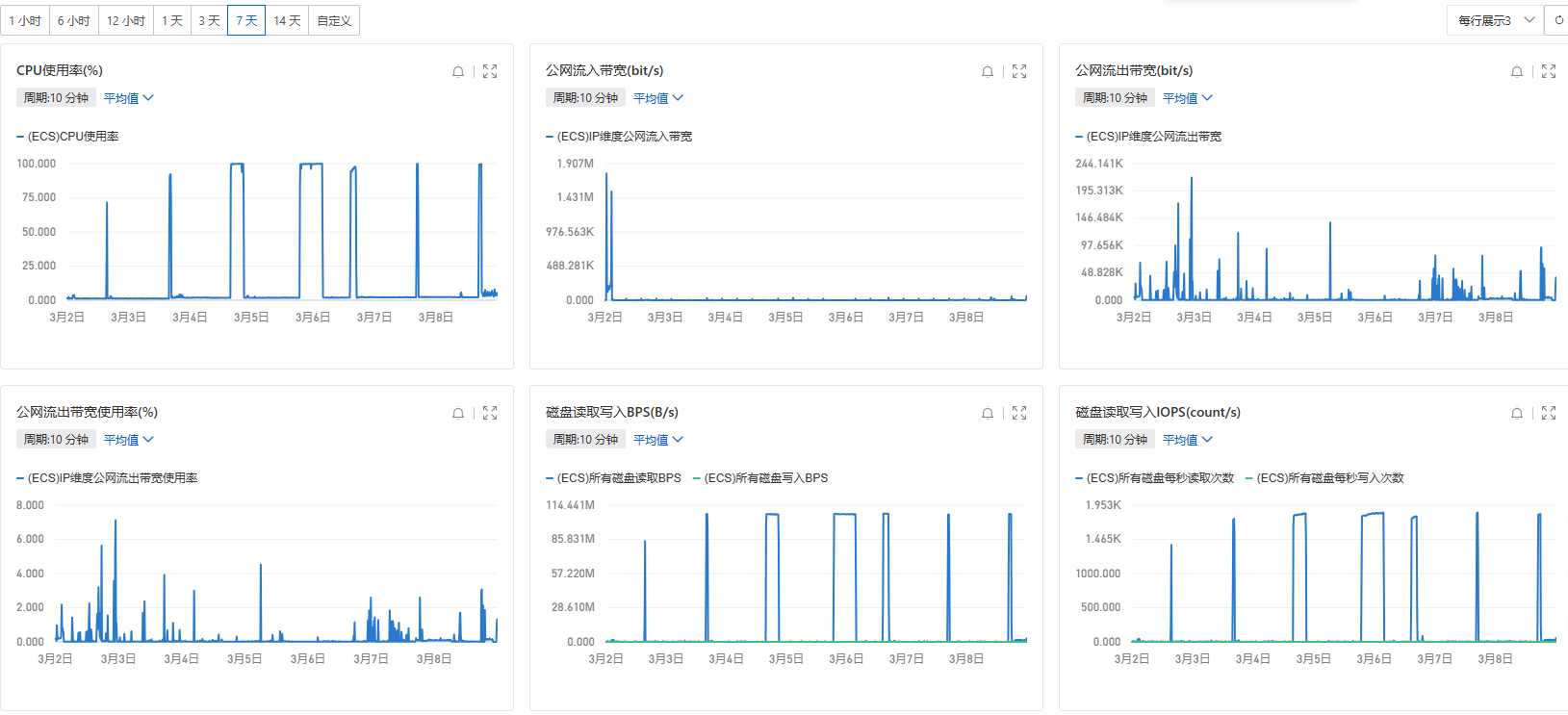
问题发生后在阿里云社区搜索发现截至2024年3月依然有大量用户反馈存在相同情况,且仍然没有一个好的解决办法
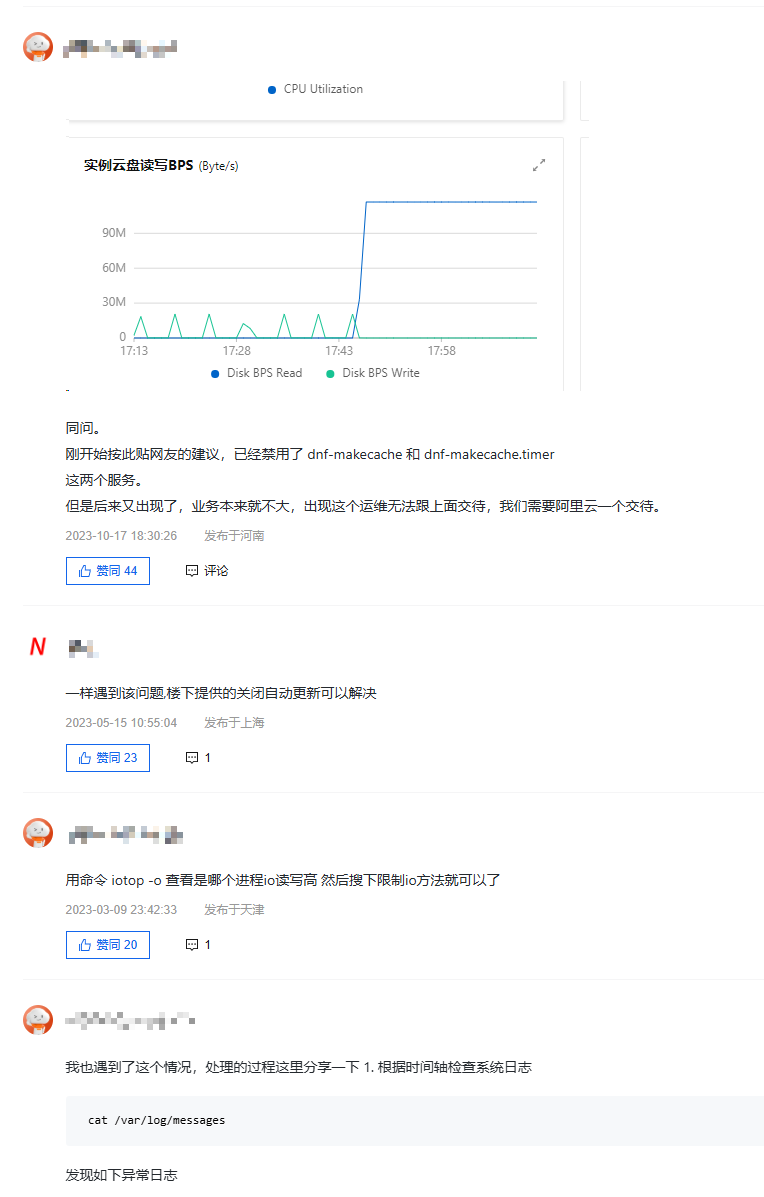
社区中大家给出的办法基本上都是禁用dnf makecache服务,但这显然不是关键。
故障分析及溯源
直觉
本打算先进入系统再利用ps、top等排查cpu占用进程情况,奈何几番尝试连接无果,只能先进行重启操作,打算在重启后再通过系统日志分析原因,执行
cat /var/log/messages在最终时间点日志如下:
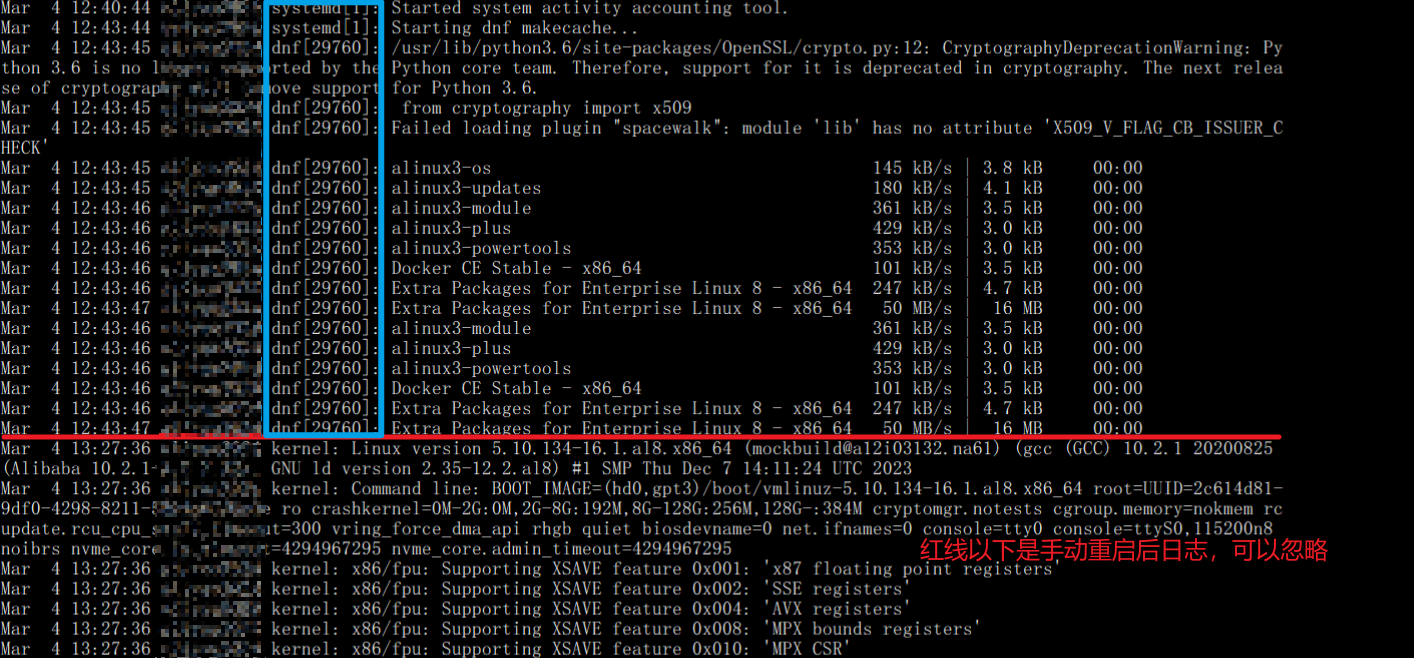
不难发现,最后系统是由一个叫做dnf 的进程执行一个名为makecache的操作,那么见微知著自然而然我们就会想到有可能是这个名为dnf的进程引发的,然而让我一度感到疑惑的是为什么一个小小的进程会在短时间内引发CPU占用飙升以及大量的云盘读写呢?穷思不得其解,遂向阿里云售后工程师提交了第一张工单,得出的结论是docker相关的占用导致内存溢出,对此我还是抱有一些疑惑,所有docker容器自开机就都处于运行状态,在没有业务压力的情况下,为什么会在各项参数平稳运行(包括内存、cpu,云盘io等)的情况下突然因内存溢出宕机?,cpu占用又是因何而几乎直线上升?高额的云盘读写又是因何而来?对于这些问题在与阿里工程师电话沟通过后依然无法准确回答,最终在阿里工程师的建议下,我使用atop以求对系统相关资源进行更详细的记录和日志溯源,静静等待问题的复现。
山重水复疑无路
仅仅一天后,守株待兔战法就获得了阶段性成果,问题果然再次出现,一样的宕机一样的ssh失联,我几乎是以光速完成了实例的重启流程,急不可耐的想要探寻一切的真相,ssh登录——成功!
执行
atop -r /var/log/atop/atop_2024XXXX查看日志——成功!
前进至下一个时间点——前进——前进——前进——>>>14:05:30成功! ············WTF!w(゚Д゚)w 我的日志呢!!!,┏┛墓┗┓...(((m -__-) 缓了几分钟我不得不相信atop竟然也在关键点栽了!,这熟悉的无力感是怎么回事😭,就这样我心有不甘的提交了第二次工单,这次工程师给出的答复依然是内存不足,但是引起的原因却变成了mysql服务,而对于mysql占用及cpu负载上升则疑似归因于网站访问量增大,但是对于我的实际而言,这个理由就比较牵强了,不说我的小破站到目前文章为数不多,就是说也还没有公开分享过任何网站链接啊,通过第三方工具也证实了那可怜的几个访问不过是我日常用的终端平板手机测试网站效果带来的,真的没有人偷偷访问的说。至此一切仿佛又回到了原点。
柳暗花明又一村
人为刀俎,我为鱼肉,VPS它它它又宕机了,虽然不抱什么希望,我还是同上次一样仔细查看了atop的历史日志,万幸好运终于降临,这一次日志完整的记录下了整个事发过程,有如神助!
执行上述命令查看日志
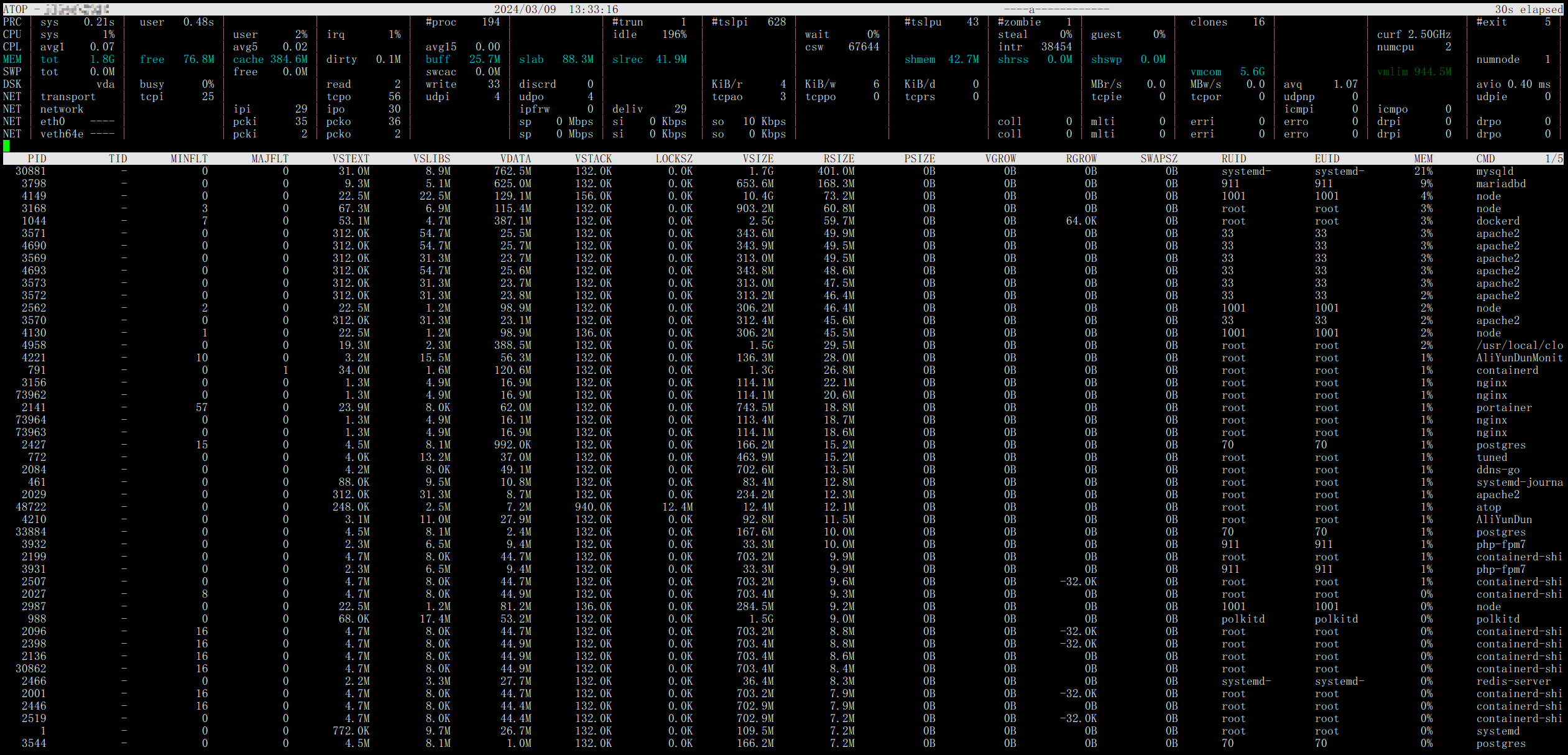
上面这张图是故障还未发生时的内存视图日志,可以发现虽然此时并没有出现故障,但是上方内存资源MEM一栏依然用蓝色字体提示我们内存可能比较紧张了,果然2G的内存还是比较乏力的(所以到底还是因为穷吗哈哈哈),再看下栏第一行提示我们此时内存资源占用大户确实是mysqld,占用了近20%,往前回溯也基本都处于这个水平,可见阿里售后把内存溢出归因于mysqld也是有道理的,后文也将对mysql占用内存的问题进行优化。
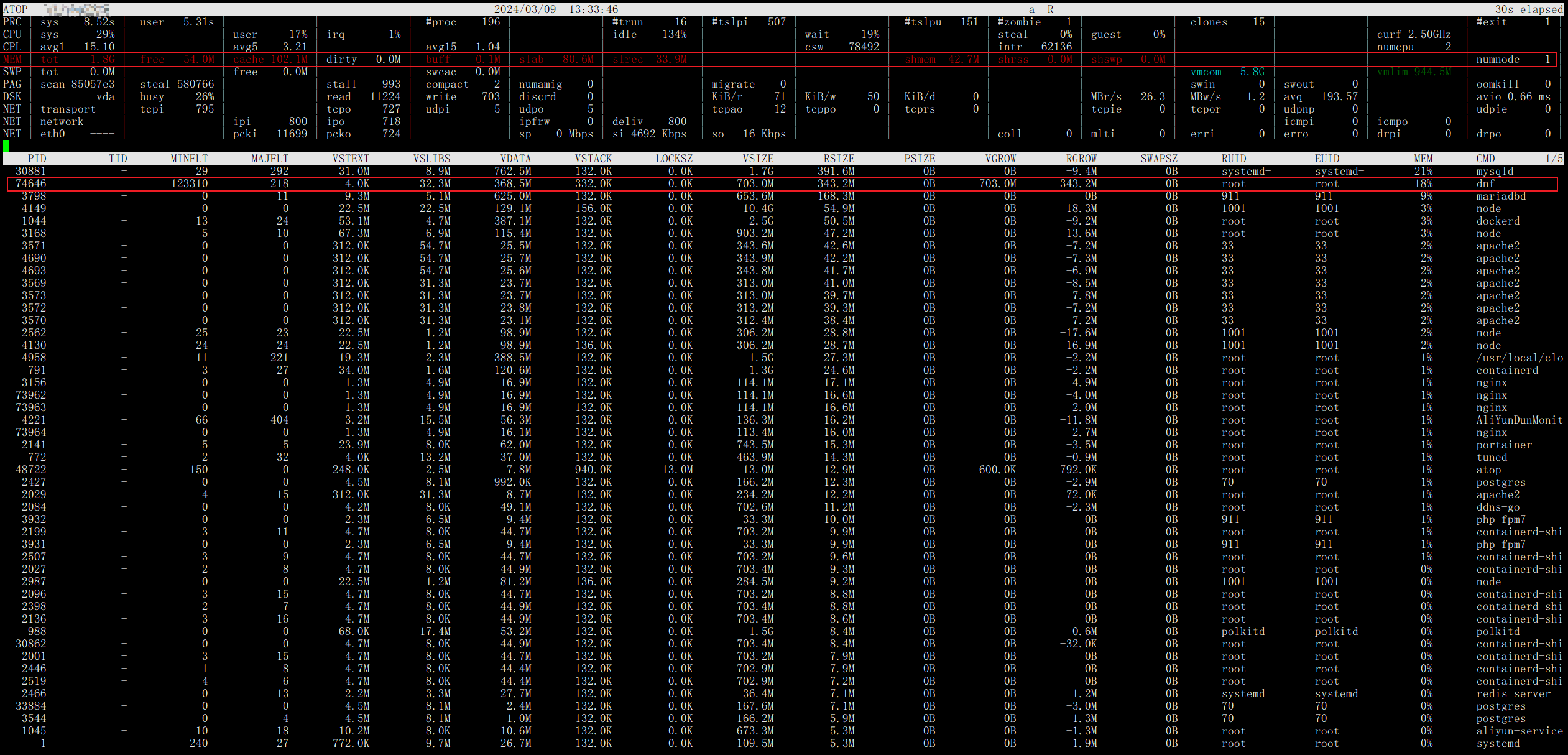
到了这一时刻,上栏内存行转红,预示内存情况已经到了生死攸关的地步,这里我们注意对比第一张图主要区别是cache和buff项大量减少,那么为什么这样?首先我们要知道什么是cache/buff,简单来说cache/buff是被设计用来在内存/硬盘进行读写操作时作为数据缓存使用,在内存充足时可以加快数据读写速度,然而在内存即将耗尽时,linux会触发内存回收,以便快速释放内存给急需进程使用,因而只能牺牲这部分作为催化剂的cache/buff,最终也就导致了我们所见的cache/buff突然降低,此外这种释放操作并非没有代价,缓存的清除往往对应着系统IO的飙升,因为系统内核要比对cache中的数据和硬盘上的数据是否一致,如果不一致则需要先进行写回操作之后才能进行回收,而这也与我们最开始的故障表现相吻合——短时的大量云盘IO。
现象解释完毕,接下来处理本质,观察下栏的详细内存视图,可以发现一个熟悉的身影——dnf,终于历尽千辛万苦最终一切还是指向了当初的直觉(莫名想起了高中时期老师的教诲,选择题犹豫不定时要相信直觉,选了就不要再改了,可惜直到如今我也没能控制住答完题手贱的本能QAQ),继续观察发现dnf进程对应的列,发现VGROW,RGROW分别指代的虚拟内存增长和实际内存增长几乎是0.5G的数量级,这对于本来就所剩无多的内存几乎是灾难性的结果,右侧所示的内存占用达到了18%,几乎相当于另一个mysqld了,也就无法避免的导致了溢出。
当然,说到这里好像还是没有解释通为什么CPU占用会直线上而且一直居高不下,毕竟即使内存溢出,操作系统也会强制杀死某些业务进程(大义灭亲?),让系统能够快速恢复正常运行。
关于kswapd、swap、vm.swappiness以及一切谜团的真相
由于我水平有限,以下分析和结论仅供小伙伴们参考,如果小伙伴们有不同意见,欢迎随时留言一起探讨~
由于dnf进程占用内存导致的溢出缺口巨大,前文提到系统内核已经很努力的试图回收缓存来堵上这个缺口,下图位于CPU占用榜首的kswapd0进程也证明了这一观点,该进程是在操作系统虚拟内存管理中负责换页的,当物理内存告急时,内核会释放缓存cache/buff里的一些闲置程序,将它们存放到swap中。
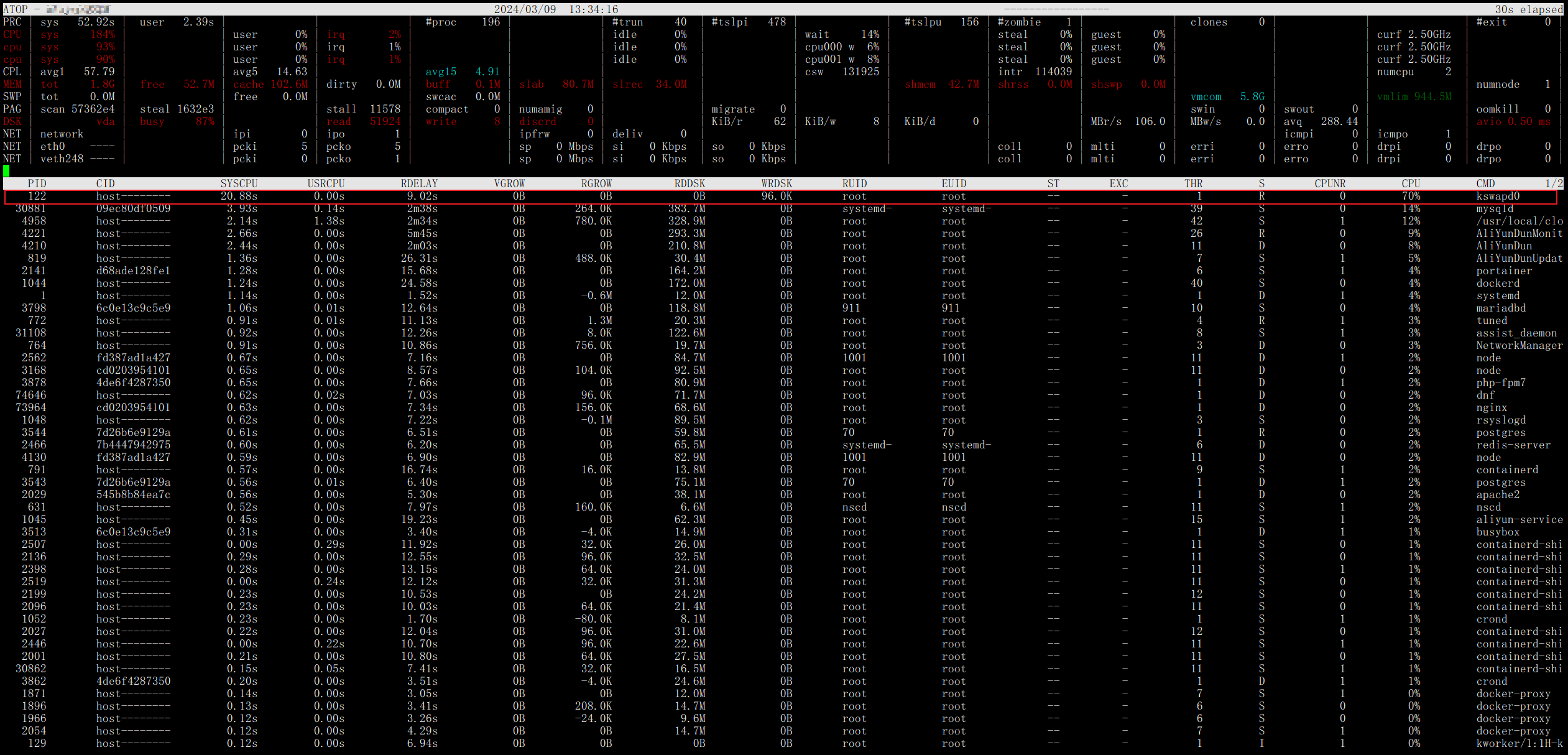
那么什么是swap呢,简单为大家介绍一下,swap指的是一块用于数据交换的空间,如果大家曾经手动安装过Linux系统的话,在初始化分区设置界面,我们常常会挂载一个swap分区,它主要是为了防止系统内存溢出(OOM)等,体积无需太大,但意义非凡。具体的回收细节这里就不再展开,小伙伴可以自己查阅资料或是点击文末的链接详细了解
当然,说到这里就不得不提一个与之相关性极高的概念——vm.swappiness
看到这个词我第一个联想到的词是happiness,也许是因为它们都有着与程度相关的后缀iness,因此我们也可以非常直观的将它理解为进行swap交换操作的程度,换句话说当vm.swappiness值越大(0-100),操作系统就越倾向于频繁利用swap分区来进行内存回收,当然,swappiness只是一个倾向参考值,当某一进程申请的内存大于当前空闲内存时,即使swappiness被设置为0,虽然操作系统极不情愿(。>︿<)_θ,但仍然会使用swap分区来存放释放cache/buff过程中的一些数据。这个值正常来说在Linux当中默认为60。
ok 洋洋洒洒讲到这里,我觉得一切的真相已是咫尺之间,不知道大家是否注意到上图左上方的概览有着奇怪的一行,截之如下

SWP很明显代表着交换分区,但关键是后面跟着的标签 tot: 0.0M ,啊啊?感情这是压根就没有swap分区呀!,我还不信邪,又在终端查询了一下
执行
free -h
sysctl -a |grep vm.swappiness结果如下

铁证如山!,但是转念一想云服务器操作系统是开箱即用的,该不会默认就没有给交换分区留空间吧,后面经过查证确实如此,阿里云社区解释的理由如下:
Swap分区或虚拟内存文件,是在系统物理内存不够用的时候,由系统内存管理程序将那些很长时间没有操作内存数据,临时保存到Swap分区虚拟内存文件中,以提高可用内存额度的一种机制。当那些程序要再次重新运行时,会再从Swap分区或虚拟内存文件中恢复之前保存的数据到内存中。
相关操作会导致额外的IO开销,特别是,如果内存使用率已经非常高,而同时IO性能也不是很好的情况下,该机制其实会起到相反的效果:不仅系统性能提升较小(因为内存使用率已经非常高了),而且由于频繁的内存到SWAP的切换操作,会导致产生大量额外的IO操作,导致IO性能进一步降低,最终反而降低了系统总体性能。
同时,为了保证服务器数据安全性和可靠性,阿里云ECS云磁盘使用了分布式文件系统作为云服务器的存储,对每一份数据都进行了强一致的多份拷贝。但是,该机制在保证用户数据安全的同时,由于3倍增涨的IO操作,会导致本地磁盘的存储性能和IO性能要弱一些。
综上,为了避免当系统资源不足时进一步降低ECS云磁盘的IO性能,所以ECS Windows默认没有启用虚拟内存,Linux默认未配置SWAP分区。不难看出,阿里云ECS默认未配置SWAP是出于总体性能的考虑,但对于我这种内存本身不大的服务器,没有SWAP分区也同时意味着可能会发生内存溢出或者其他更致命的问题——当内存不足时,kswapd进程被激活,并且不得不试图对缓存数据执行swap操作,然而好巧不巧云服务器刚好默认未配置swap分区,即可用于交换的空间为0,最终两者的矛盾导致kswapd进程陷入死循环,从而反映到操作系统就最终表现出CPU占用飙升,且永无止境,直到手动强制重启。
至此,一切皆以明了!
故障修复
知己知彼,百战不殆,既然源头已知,则按图索骥,修复自然信手拈来,当然这其中也有一些取舍和折中,大家视自己情况而定。
DNF进程问题
仅从问题发生的直接诱因来看,dnf进程正在执行的makecache命令是为关键,那么什么是dnf呢?makecache又是怎样的行为?查找资料发现dnf是一种包管理器,同时是yum的下一代版本,主要用于在基于Fedora、CentOS和其他使用RPM软件包格式的Linux发行版上安装、升级和删除软件包。其在以下情况下可能会导致大量占用内存:
- 包更新或安装: 当你使用 dnf 进行包的更新或安装时,dnf 进程会在后台执行操作。这些操作可能涉及下载、解压、依赖解析等多个步骤,这可能会导致 dnf 进程消耗较多的内存资源。
- 元数据更新: dnf 会定期更新软件仓库的元数据信息,以确保系统中的软件列表是最新的。在更新元数据时,dnf 进程可能需要占用大量内存来处理和解析软件包的元数据。
- 依赖解析: 在安装或更新软件包时,dnf 会对软件包的依赖关系进行解析,以确保安装的软件包能够正常运行,并满足其他软件包的依赖关系。这个过程可能会占用较多的内存资源,特别是当有许多软件包需要安装或更新时。
了解了这些我们再来看make cache命令,它用于更新本地软件包仓库的缓存。在使用 dnf 包管理器时,软件包仓库的元数据(metadata)是存储有关可用软件包的信息的重要部分。这些元数据包括软件包的名称、版本、依赖关系、描述等。而dnf makecache 命令的作用是强制 dnf 重新生成本地软件包仓库的元数据缓存。重点来了,在系统中存在一个计时器来定期更新仓库的元数据缓存,在内存本就不充裕的情况下,这部分的内存占用恰恰导致了内存溢出的结果。
因此,我们只需关闭dnf-makecache的计时器即可
终端执行
systemctl stop dnf-makecache.timer
systemctl disable dnf-makecache.timerSwap交换区问题(本质原因)
根据上文的分析,刨根究底,阿里云ECS默认未配置swap交换区是导致进程陷入死循环的根本原因,要解决当然也很容易,只需手动配置swap即可!但是由于我的系统是搭建在普通云盘上的,阿里云不建议普通云盘配置swap交换区,我猜测可能是因为普通云盘是机械盘,读写很慢,会增加io时长?如果大家使用的是高效云盘或是SSD云盘,可以尝试配置一个swap分区从根本上解决问题,我就不进行该项配置了,放一个阿里云官方的配置链接供小伙伴们参考《Linux实例SWAP分区的配置和常见问题处理》
MySQL 8.0占用大量内存问题
通过atop日志可以注意到在正常运行的情况下,mysqld进程的内存占用也达到了20%+,相对于MySQL5.0有了相当一部分增加,优化的思路主要是关闭performance_schema,顾名思义它是用来进行性能分析的,但是此时是一个博客应用场景,并非实际的业务开发,性能分析显然是冗余的。因此只需在mysql配置文件中将该参数设置为off即可。
# 在mysql配置文件my.cnf中找到或者加上下面的参数
performance_schema = off保存后记得重启mysql服务或者docker容器
由于系统中还有一个用于其他服务的数据库--mariadb,我也顺手进行了上述配置
优化后的atop监视图如下:
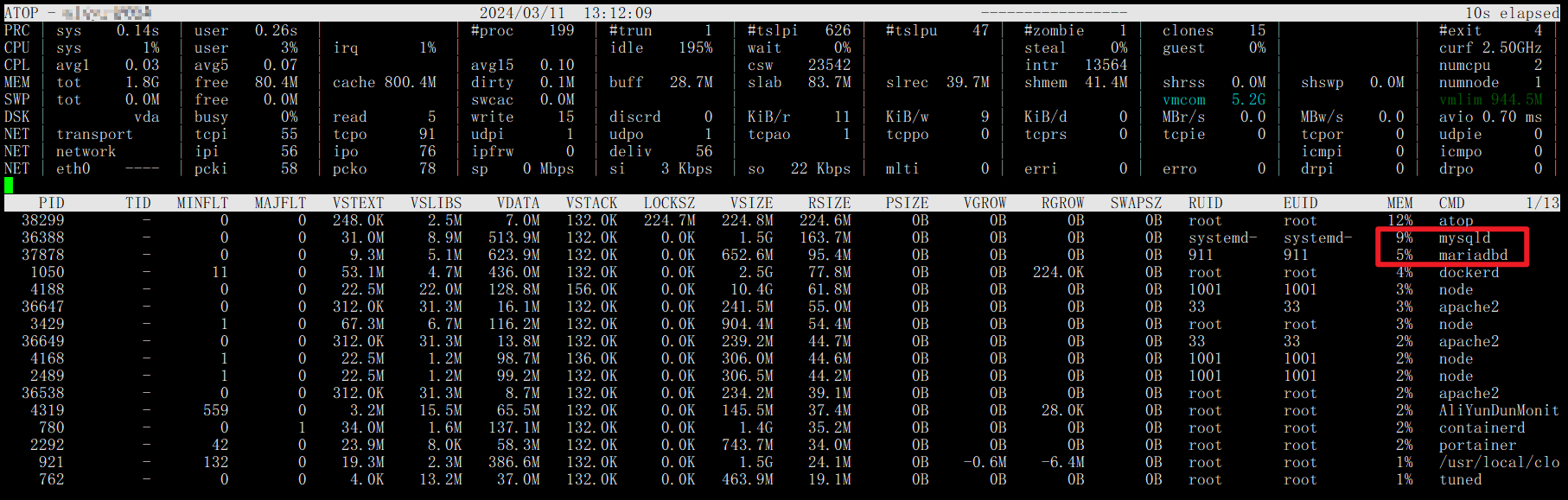
效果可谓立竿见影!!!,mysql进程内存占用从21%左右直线下降到9%,降幅高达57%,maria进程内存占用也近乎腰斩,终于行将就木的可怜内存又重新焕发了生机!
效果评估
截至25年2月,应用上述方案后服务器成功稳定运行1年啦!
截至今日,距离应用上述修复措施已有七曜,期间各项服务没有再宕机过,CPU占用及内存也都一切正常,这次的故障修复到此也圆满的画上句点,终于是解决了心腹大患哈哈,小伙伴们的服务器如果出现类似情况也可以参考一二 ~(≧∀≦)ゞ
日志
2024-03-09 初稿及初步解决方案实测
2024-03-11 新增MySQL内存优化
2024-03-12 新增docker数据库配置细节
2025-02-23 新增了一些备注,完善了行文细节
