情感计算简介
情感计算是人类情感情绪及其分析过程的总称,其概念由Prof. Picard于1997年提出,主要应用于建立认知智能系统,让计算机可以准确识别人类的情感并快速做出恰当回应,其典型的应用场景如下:
- 智能汽车系统:用于实时监测驾驶员的情绪状态并在必要时根据识别结果迅速做出回应,例如检测疲劳驾驶、情绪过激等显著影响行车安全的情感状态,快速做出回应以降低事故发生的可能性。
- 机器人情感引擎:赋予机器人情感的读取以及表达能力,让其具有情感智能,为人类提供可能的情绪价值并可以对人类情感和周围环境变化做出迅速回应。
情感计算主要涉及两个主题,一是情感识别(emotion recognition),其目标是检测人类的情感状态,主要侧重于视觉情感识别(VER)/音频情感识别(AER)/生理情感识别(PER),二是情绪分析(sentiment analysis),其主要侧重于社会事件、营销活动、产品偏好当中的文本评价和观点挖掘,其结果通常有三种即积极、消极或中性。这两者在实际应用时可以同时部署。
研究表明,人类情绪主要通过面部表情(55%),声音(38%),语言(7%)来表达,统称为身体情感数据,由于人们倾向于在社交媒体或生活中表达自己,因此这些数据比较容易收集,但因为人们在一些情况下可能会掩饰隐藏自己的真实情绪所以得到的情感数据不一定可靠。相比之下,人类的生理信号数据(例如脑电波和心电图等)很难自发改变,基于此的情绪识别可以实时生成更加客观的预测,并提供可靠的情绪状态特征。
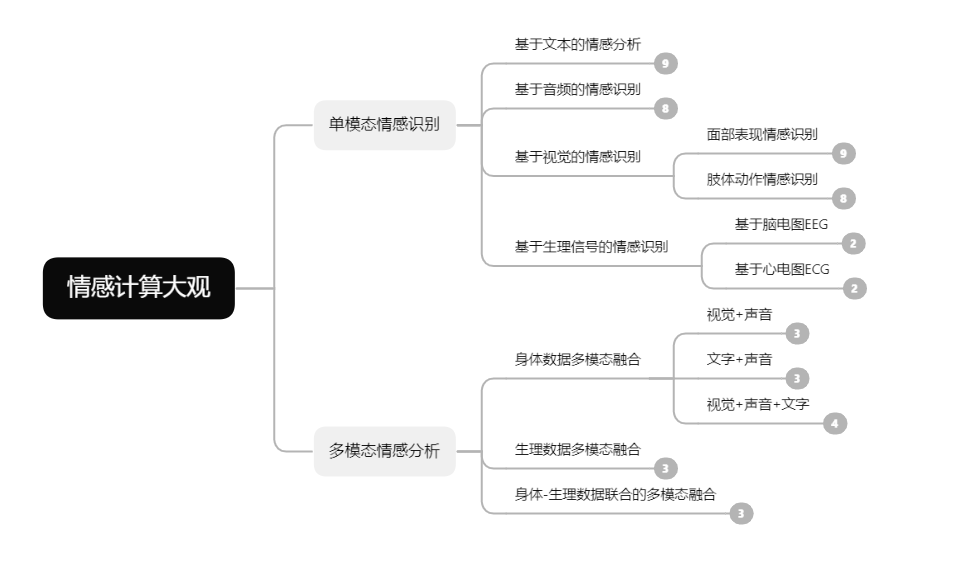
在以往的研究当中由于人的生理数据不易获得,大多数情绪识别方法都是基于上述的身体情感数据,而近年来随着可穿戴设备的不断普及,多模态生理信号例如脑电图(EEG),心电图(ECG)、肌电图(EMG)等数据来源大大增加(ps:目前确实有很多智能手表具备ECG监测功能,就是价格上┭┮﹏┭┮),由此催生出一个新的研究热点,即基于生理信号的情绪识别和身体数据-生理数据融合的情感分析。下图是对目前情感计算的研究分支结构做一个简单呈现,当然这是以2020年的视角来看的,放眼今日,大模型几乎改变了所有研究领域,多模态带来的性能提升以及应用场景是在以往的研究中难以企及的,下文也会就此进行展开。
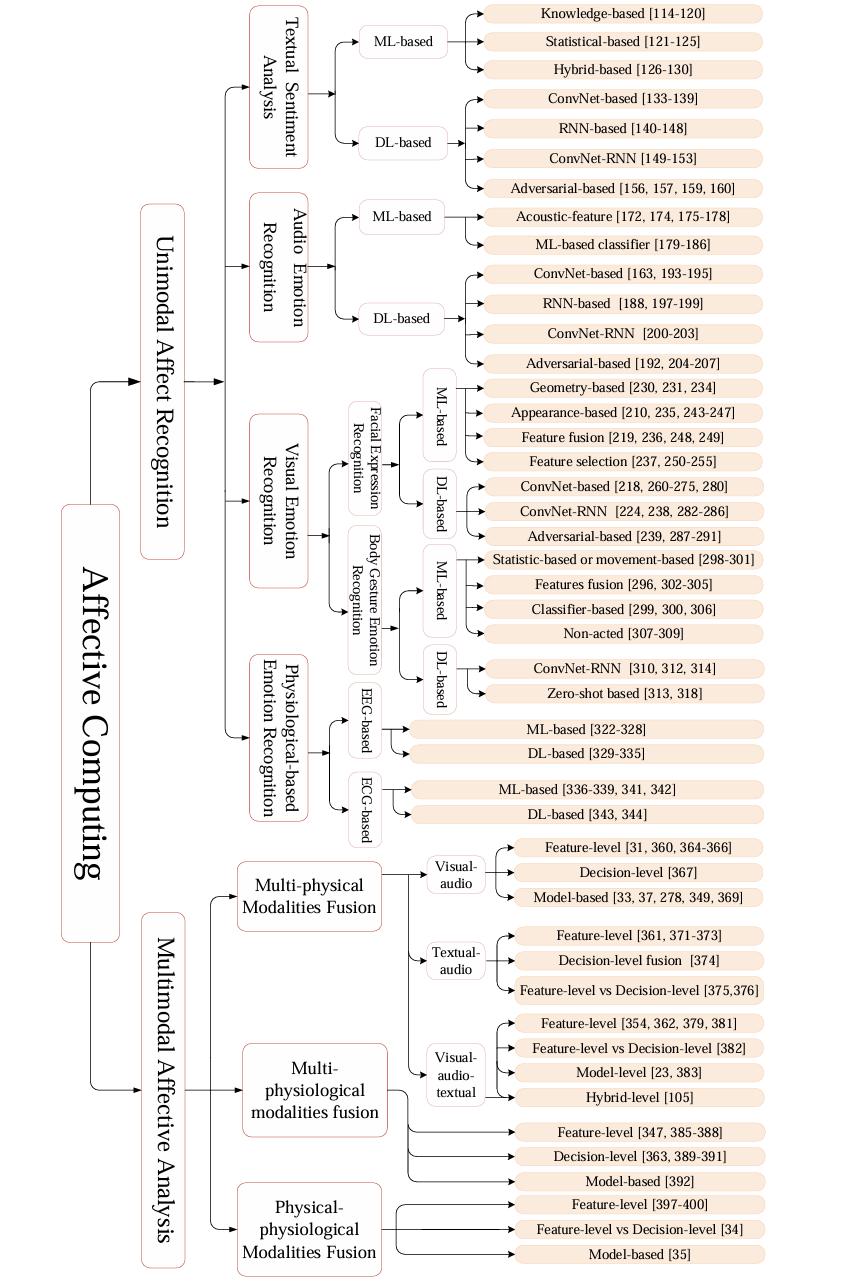
简化版
情绪模型简介
情感的基本概念由Prof. Ekman在20世纪70年代提出,虽然在过去的几十年中科学家不断尝试用不同的方式对情绪进行分类,但截至今日学界仍然没有统一的情绪模型,因此目前一般的研究都是建立在两类通用情绪模型之上的,即离散情绪模型(Discrete emotion model)和维度情绪模型(dimensional emotion model)也称连续情绪模型(continuous emotion model)
离散情绪模型
所谓离散即将情绪定义为有限的类别,目前广泛使用的分类主要由两种,Ekman的六种基本情绪模型以及Plutchik的情绪轮模型,如图
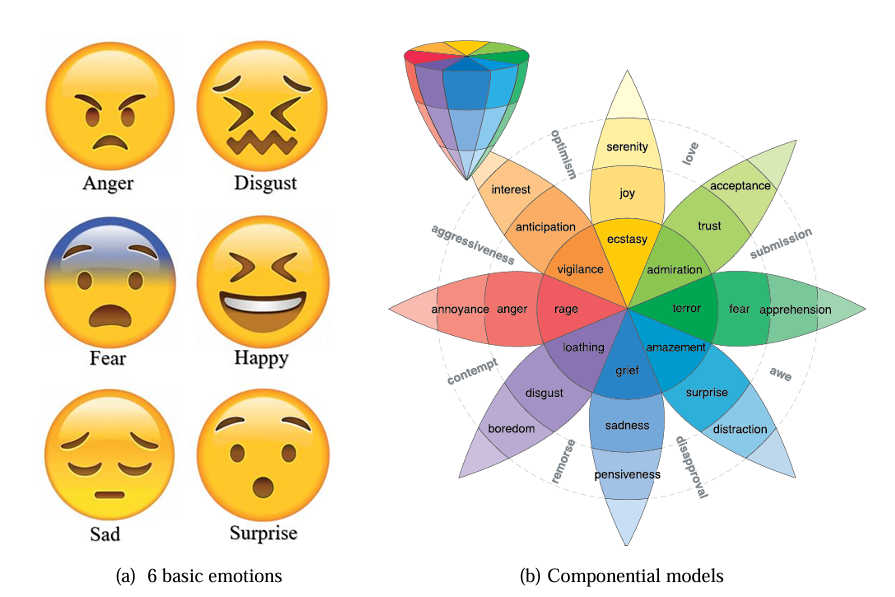
具体而言,Ekman模型中的六种情绪包括愤怒、厌恶、恐惧、快乐、悲伤和惊讶,它的推导主要涉及人类的本能和相同语义下表达的一致性,这里不再过多赘述,相比而言,Plutchik的情绪轮模型主要涉及八种情绪,即喜悦、信任、恐惧、惊讶、悲伤、期待、愤怒和厌恶,他们之间存在对立等相互关系并可由此衍生出更复杂的复合情绪,例如喜悦与悲伤呈现对立关系,该模型也被称为成分模型,典型的特点是较强的情绪占据中心,较弱的情绪更靠近外围。
离散情绪通常可以分为三种极性,即正面、负面与中性,他们广泛被用于情绪分析。
维度情绪模型
当然,离散化的局限性显而易见,因此多维模型同样被广泛采用,其中最受认可的是愉悦-唤醒-支配模型(Pleasure-Arousal-Dominance)也叫PAD模型,其中愉悦维度表示人类的快乐程度,值域从极其痛苦到狂喜,唤醒维度用来衡量生理活动和心理警觉水平,而支配维度则表示影响周围环境和他人亦或被他人和环境影响程度。
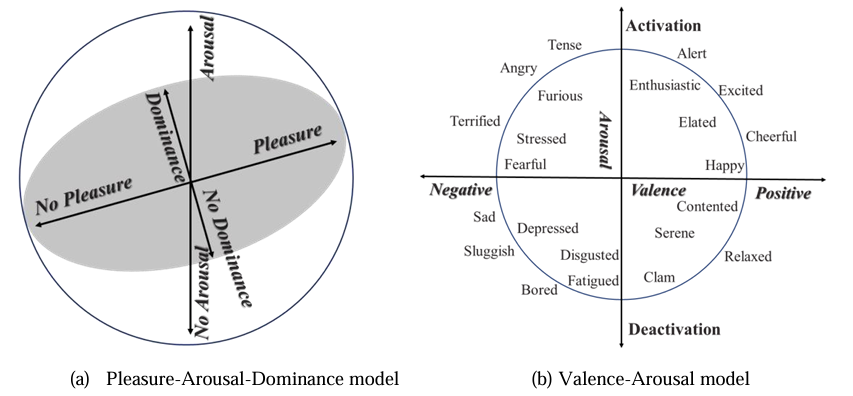
由于PAD模型中的愉悦和唤醒两个维度足以表达绝大多数情绪,Russell提出了一个基于效价-唤醒(Valence-Arousal )的模型也称VA模型,该模型定义了一个连续的二位情绪空间,以效价和唤醒度为轴,其由四个象限组成,第一象限为高唤醒,效价为正,表示快乐相关的情绪,第三象限为低唤醒都和负效价,与悲伤情绪相关,以此类推第二象限与愤怒情绪相关,第四象限与平静情绪相关。
情感计算前沿现状
在2020年以前,大部分关于情感计算的研究都是基于传统的ML或DL方法,但随着LLMs的快速迭代,多模态逐渐成为了学术和工业界的主流,最近看到了稚晖君在B站发布了智元机器人最新产品灵犀 x2,在介绍交互智能时提到了其采用了Reaction-Agent情感计算引擎,可见在实际应用中智能体带来的多模态信息处理及反馈能力远比传统的单模态ML/DL模型更具泛化性,当然并不是说传统的单模态机器或深度学习模型就彻底落后了,他们在某些细分领域如文本音频视觉情感分析、身体和生理信号情绪识别等等可能仍然具有比多模态更高的识别准确率,只是就实际应用而言基于多模态的情感计算方法会是当下和可预见未来的研究热点,毕竟更好的任务泛化性意味着更低的成本和更高的经济效益,而这恰恰也是新技术落地的必经之路。因此作为一篇大观性的博文这里不再赘述情感计算以往的路线和辉煌,仅仅聚焦近5年来学界前沿的技术应用和突破性概念的提出。
2022 ACM MM
-
Leveraging Multi-modal Interactions among the Intermediate Representations of Deep Transformers for Emotion Recognition
- 主要创新点:提出了多模态的递归中间层聚合(RILA)模型,以探索利用深度预训练转化器的中间表征之间的多模态互动来实现端到端的情感识别的有效性。
- 主要内容:现有的端到端模型通常在最后一层融合单模态表示,而不利用中间表示之间的多模态互动。因此我们提出了多模态的递归中间层聚合(RILA)模型,以探索利用深度预训练转化器的中间表征之间的多模态互动来实现端到端的情感识别的有效性。我们模型的核心是中间表征融合模块(IRFM),它由多模态聚集门控模块和多模态标记注意模块组成。具体来说,在每一层,我们首先使用多模态聚合门控模块来捕捉跨模态和跨层的语料级互动。然后,我们利用多模态标记关注模块来利用标记级的多模态互动。在IEMOCAP和CMU-MOSEI上的实验结果表明,我们的模型达到了最先进的性能,充分地利用了中间表征之间的多模态相互作用。
-
Towards Unbiased Visual Emotion Recognition via Causal Intervention
- 主要创新点:为了缓解数据集偏差带来的负面影响,提出了一种新型的干预性情感识别网络(IERN)来实现后门调整,这是因果推理中的一种基本去混淆技术。
- 主要内容:尽管在视觉情感识别方面已经取得了很大的进展,但现代深度网络倾向于利用数据集特征来学习输入和目标之间的虚假统计关联。这样的数据集特征通常被视为数据集偏见,它损害了这些识别系统的鲁棒性和泛化性能。在这项工作中,我们从因果推理的角度仔细研究了这个问题,这种数据集特征被称为混淆因素,误导系统学习虚假的关联。为了缓解数据集偏差带来的负面影响,我们提出了一种新型的干预性情感识别网络(IERN)来实现后门调整,这是因果推理中的一种基本去混淆技术。具体来说,IERN首先将与数据集相关的背景特征与实际的情绪特征分开,其中前者构成混淆因素。然后,情绪特征将被迫在被送入分类器之前平等地看到每个混杂因素的分层。一系列设计的测试验证了IERN的功效,在三个情感基准上的实验表明,IERN在无偏见的视觉情感识别方面优于最先进的方法。
-
Disentangled Representation Learning for Multimodal Emotion Recognition
- 主要创新点:提出了一种特征分解的多模态情感识别(FDMER)方法,该方法为每种模态学习共同和私有的特征表征。
- 主要内容:多模态情感识别旨在从文本、音频和视觉模态中识别人类的情感。以前的方法要么探索不同模态之间的相关性,要么设计复杂的融合策略。然而,严重的问题是,分布差距和信息冗余往往存在于异质模态之间,导致学到的多模态表征可能是不完善的。在这些观察的激励下,我们提出了一种特征分解的多模态情感识别(FDMER)方法,该方法为每种模态学习共同和私有的特征表征。具体来说,我们设计了共同的和私有的编码器,将每个模态分别投射到模态不变的子空间和模态特定的子空间。模态不变的子空间旨在探索不同模态之间的共性,并充分减少分布差距。特定模态子空间试图加强多样性,并捕捉每种模态的独特特征。之后,引入一个模态判别器,以对抗性的方式指导共同和私有编码器的参数学习。我们通过为上述子空间设计定制的损失来实现模态一致性和差异性约束。此外,我们提出了一个跨模态注意力融合模块,以学习自适应权重,从而获得有效的多模态表征。最终的表征被用于不同的下游任务。实验结果表明,FDMER在两个多模态情感识别基准上的表现优于最先进的方法。此外,我们通过对多模态幽默检测任务的实验进一步验证了我们模型的有效性。
-
A Multi-view Spectral-Spatial-Temporal Masked Autoencoder for Decoding Emotions with Self-supervised Learning
- 主要创新点:提出了一种基于自监督学习的多视角光谱-空间-时间掩码自动编码器(MV-SSTMA),以解决这些数据标注耗时和脑电信号敏感的挑战。
- 主要内容:情感型脑机接口已经取得了相当大的进展,研究人员可以成功地解释在实验室环境中收集的有标签和无缺陷的EEG数据。然而,脑电图数据的注释是很耗时的,需要大量的劳动力,这限制了在实际场景中的应用。此外,由于脑电信号对噪声很敏感,每天收集的脑电数据可能会被部分损坏。在本文中,我们提出了一种带有自我监督学习的多视角光谱-空间-时间掩码自动编码器(MV-SSTMA),以解决这些日常应用的挑战。MV-SSTMA是基于一个多视图CNN-变换器的混合结构,从光谱、空间和时间的角度解释EEG信号的情感相关知识。我们的模型由三个阶段组成。1)在通用预训练阶段,来自所有受试者的未标记的EEG数据的通道被随机屏蔽,随后被重建,以从EEG数据中学习通用的表征;2)在个性化校准阶段,只有来自特定受试者的少数标记数据被用来校准模型;3)在个人测试阶段,我们的模型可以从健全的EEG数据中解码个人情绪,也可以解码通道丢失的受损情绪。在两个开放的情绪脑电数据集上进行的广泛实验表明,我们提出的模型在情绪识别方面取得了最先进的性能。此外,在通道缺失的异常情况下,我们提出的模型仍然可以有效地识别情绪。
-
Unsupervised Domain Adaptation Integrating Transformer and Mutual Information for Cross-Corpus Speech Emotion Recognition
- 主要创新点:提出了一种无监督的领域适应方法,该方法整合了Transformer和互感信息(MI),用于跨语料库的SER。
- 主要内容:本文重点讨论了一个有趣的任务,即无监督的跨语料库语音情感识别(SER),其中标记的训练(源)语料库和未标记的测试(目标)语料库具有不同的特征分布,导致源域和目标域之间存在差异。为了解决这个问题,本文提出了一种无监督的领域适应方法,该方法整合了Transformer和互感信息(MI),用于跨语料库的SER。首先,我们的方法采用变形器的编码层,从提取的段级对数-梅尔频谱特征中捕捉语料的长期时间动态,从而为两个域中的每个语料产生相应的语料级特征。然后,我们提出了一种无监督的特征分解方法,采用混合的Max-Min MI策略,从提取的混合语篇级特征中分别学习领域不变的特征和领域特定的特征,在此过程中,两个领域之间的差异被尽可能地消除,同时保留了它们各自的特征。最后,设计了一个交互式多头关注融合策略,以学习领域可变特征和领域特定特征之间的互补性,从而使它们可以交互式地融合到SER中。在IEMOCAP和MSP-Improv数据集上的大量实验表明,我们提出的方法在无监督的跨语料库SER任务上是有效的,超过了最先进的无监督的跨语料库SER方法。
-
Feeling Without Sharing: A Federated Video Emotion Recognition Framework Via Privacy-Agnostic Hybrid Aggregation
- 主要创新点:为了缓解异质性数据,本文提出了EmoFed,这是一个通过多组聚类和隐私无关的混合聚合来进行基于视频的情绪识别的联邦学习的实用框架。
- 主要内容:视频数据的爆炸性增长给情感识别带来了新的机遇和挑战。视频情感应用具有巨大的商业价值,但可能涉及对个人情感的非法窥探,导致了对隐私保护的争议。联合学习(FL)范式可以大大解决公众对视频情感识别中数据隐私的日益关注。然而,由于任务的独特性,传统的联合学习方法表现不佳:由情感标签倾斜和跨文化表达差异引起的数据在客户之间是异质的。为了缓解异质性数据,我们提出了EmoFed,这是一个通过多组聚类和隐私无关的混合聚合来进行基于视频的情绪识别的联合学习的实用框架。它在保护隐私的同时,产生了一个普遍适用和改进的模型,它在群组感知的个性化聚合下训练本地模型。为了进一步鼓励在客户之间交流全面和隐私无关的信息,我们将全局层和个性化层的模型参数上传到服务器。我们对个性化层采用同态加密的方法,由于在加密/解密过程中没有噪音被添加到模型更新中,因此不会产生学习精度的损失。所提出的方法适用于基于视频的情绪识别任务,以预测演员的情绪表达和观众的诱导情绪。在四个基准上进行的大量实验和消融研究证明了我们方法的有效性和实用性。
-
EASE: Robust Facial Expression Recognition via Emotion Ambiguity-SEnsitive Cooperative Networks
- 主要创新点:为了解决情绪的模糊性问题,提出了情感模糊-敏感合作网络(EASE)。
- 主要内容:面部表情识别(FER)在现实世界的应用中起着至关重要的作用。然而,在野外收集的大规模面部表情识别数据集通常包含噪音。更重要的是,由于情绪的模糊性,具有多种情绪的面部图像很难从具有噪声标签的图像中区分出来。因此,为FER训练一个健壮的模型是很有挑战性的。为了解决这个问题,我们提出了情感模糊-敏感合作网络(EASE),它包含两个部分。首先,对模糊性敏感的学习模块将训练样本分为三组。两个网络中损失小的样本被认为是干净的样本,而损失大的样本是有噪声的。注意对于一个网络不同意另一个网络的冲突样本,我们利用情绪的极性线索,将传达模糊情绪的样本与有噪音的样本区分开来。在这里,我们利用KL散度来优化网络,使它们能够注意到非主导的情绪。EASE的第二部分旨在加强合作网络的多样性。随着训练历时的增加,合作网络将收敛到一个共识。我们根据特征之间的相关性构建了一个惩罚项,这有助于网络从图像中学习不同的表征。在6个流行的面部表情数据集上进行的大量实验表明,EASE优于最先进的方法。
-
ViPER: Video-based Perceiver for Emotion Recognition
- 主要创新点:提出了一个多模态架构,利用基于模态的变换器模型来结合视频帧、音频记录和文本注释进行情绪识别。
- 主要内容:从视频中识别人类的情绪需要深入了解底层的多模态来源,包括图像、音频和文本。由于输入的数据源在不同的模态组合中是高度可变的,利用多种模态往往需要特设的融合网络。为了预测一个人对给定视频片段的情绪唤起,我们提出了ViPER,这是一个多模态架构,利用基于模态的变换器模型来结合视频帧、音频记录和文本注释。具体来说,它依赖于一个与模式无关的后期融合网络,这使得ViPER很容易适应不同的模式。在MuSe-Reaction挑战赛的Hume-Reaction数据集上进行的实验证实了所提方法的有效性。
-
Improving Dimensional Emotion Recognition via Feature-wise Fusion
- 主要创新点:本文主要解决了在特征融合中传统方法通常忽略了细粒度的信息的问题。
- 主要内容:本文介绍了RiHNU团队对多模态情感分析(MuSe)2022年的MuSe-Stress子挑战的解决方案。MuSe-Stress是一项通过内部或外部反应(如音频、生理信号和面部表情)来辨别求职面试中的人类情绪状态的任务。多模态学习被广泛认为是多模态情感分析任务的一种可用方法。然而,大多数多模态模型未能捕捉到每个模态之间的关联,导致通用性有限。我们认为,这些方法无法建立辨别性的特征,主要是因为它们通常忽略了细粒度的信息。为了解决这个问题,我们首先通过一个特征融合机制对空间-时间特征进行编码,以学习更多的信息表示。然后,我们利用后期融合策略来捕捉多种模式间的细粒度关系。集合策略也被用来提高最终的性能。在测试集上,我们的方法对情绪和生理唤醒分别达到了0.6803和0.6689。
2023 ACM MM
- Emotion-Prior Awareness Network for Emotional Video Captioning
- 主要创新点:提出了一个情绪优先意识网络(EPAN)。它主要受益于新颖的树形结构情感学习模块,涉及目录级心理类别和词汇级常用词,以达到明确且细粒度的情感感知的目标。
- 主要内容:情感视频字幕(EVC)是一项新兴任务,用视频中表达的内在情感来描述事实内容。在字幕生成阶段有效感知微妙且模糊的视觉情感线索对于 EVC 任务至关重要。然而,现有的字幕方法通常忽视了对用户生成视频中情感的学习,从而使得生成的句子有点无聊和没有灵魂。为了解决这个问题,本文以类人感知优先的方式提出了一种新的情感字幕视角,即首先感知固有情感,然后利用感知到的情感线索来支持字幕生成。具体来说,我们设计了一个情绪优先意识网络(EPAN)。它主要受益于新颖的树形结构情感学习模块,涉及目录级心理类别和词汇级常用词,以达到明确且细粒度的情感感知的目标。此外,我们在目录级别和词汇级别之间开发了一种新颖的从属情感掩蔽机制,有助于从粗到细的情感学习。之后,在情感优先的情况下,我们可以通过利用视觉、文本和情感语义的互补来有效地解码情感描述。此外,我们还引入了三个简单而有效的优化目标,可以从情感字幕、分层情感分类和情感对比学习的角度显着促进情感学习。三个基准数据集上的充分实验结果清楚地证明了我们提出的 EPAN 在语义和情感指标方面相对于现有 SOTA 方法的优势。广泛的消融研究和可视化分析进一步揭示了我们的情感视频字幕方法的良好可解释性。
- Multimodal Emotion Interaction and Visualization Platform
- 主要创新点:提出了一种多模态情感分析平台,可以灵活地捕获、检测和分析不同情况下(包括离线和在线应用场景)多模态视频对象的情感。
- 主要内容:在本文中,我们提出了一种多模态情感分析平台,可以灵活地捕获、检测和分析不同情况下(包括离线和在线应用场景)多模态视频对象的情感。该系统可以可视化多模态和单模态环境中不同类型情绪的动态影响。所呈现的情绪分析结果显示了特定模态和多种模态的即时和时间序列状态。我们的系统通过交互式界面填补了当前多模态情感分析的研究和应用空白。值得注意的是,所构建的系统可以自适应处理预先录制的视频剪辑以及收集的真实世界数据,具有出色的实用性和交互性。
- EmotionKD: A Cross-Modal Knowledge Distillation Framework for Emotion Recognition Based on Physiological Signals
- 主要创新点:提出了 EmotionKD,这是一种跨模态知识蒸馏的框架,可以在统一的框架下同时对 GSR 和 EEG 信号的异质性和交互性进行建模。
- 主要内容:使用多模态生理信号的情感识别是情感计算的一个新兴领域,与单模态方法相比,它显着提高了性能。脑电图 (EEG) 和皮肤电反应 (GSR) 信号的结合对于客观和互补的情绪识别特别有效。然而,EEG信号采集的高成本和不便严重阻碍了多模态情感识别在现实场景中的普及,而GSR信号更容易获得。为了应对这一挑战,我们提出了 EmotionKD,这是一种跨模态知识蒸馏的框架,可以在统一的框架下同时对 GSR 和 EEG 信号的异质性和交互性进行建模。通过使用知识蒸馏,可以将完全融合的多模态特征转移到单模态 GSR 模型以提高性能。此外,提出了自适应反馈机制,使多模态模型能够在知识蒸馏过程中根据单模态模型的性能进行动态调整,从而引导单模态模型增强其在情感识别方面的性能。我们的实验结果表明,所提出的模型在两个公共数据集上实现了最先进的性能。此外,我们的方法有可能减少对多模态数据的依赖,同时降低性能损失,使情感识别更加适用和可行。
- Advancing Audio Emotion and Intent Recognition with Large Pre-Trained Models and Bayesian Inference
- 主要创新点:为 ACM 多媒体计算副语言挑战赛采用大型预训练模型,解决请求和情感共享任务。
- 主要内容:大型预训练模型在副语言系统中至关重要,可以证明情感识别和口吃检测等任务的有效性。在本文中,我们为 ACM 多媒体计算副语言挑战赛采用大型预训练模型,解决请求和情感共享任务。我们探索利用音频和文本模式的纯音频和混合解决方案。我们的实证结果一致表明混合方法相对于纯音频模型的优越性。此外,我们引入贝叶斯层作为标准线性输出层的替代。多模式融合方法在 HC 请求方面实现了 85.4% 的 UAR,在 HC 投诉方面实现了 60.2%。情感分享任务的集成模型产生的最佳 ρ 值为 0.614。本研究中探索的贝叶斯 wav2vec2 方法使我们能够轻松构建集成,但代价是仅微调一个模型。此外,我们可以拥有可用的置信度值,而不是通常过度自信的后验概率。
2024 ACM MM
-
Multimodal Emotion Recognition Calibration in Conversations
-
主要创新点:本文提出了一种用于多模态对话情绪识别的校准框架—CMERC,旨在解决现有模型在处理情绪推断时可靠性不足的问题。
-
主要内容:现有的多模态对话情绪识别(Multimodal Emotion Recognition in Conversations, MERC)研究更多地聚焦于提升指标,而在模型可靠性方面的探索却相对不足。现有方法在移除某些模态或上下文线索后,样本的预测置信度反而增加。这种反直觉现象暴露了模型在模态和上下文依赖上的不平衡,定义这类样本为不确定样本。这不仅暴露了现有方法在决策可靠性上的局限性,还违背了信息旨在消除不确定性的基本定义。本文提出了一种用于多模态对话情绪识别的校准框架—CMERC,旨在解决现有模型在处理情绪推断时可靠性不足的问题。框架的设计从三个关键校准方向入手:课程学习校准:引入课程学习策略,采用逐步训练的方法,将不确定样本逐步引入模型训练中。混合对比学习校准:设计了一种混合对比学习方法,通过增大不确定样本与其他样本之间的距离,增强模型对引起不确定性因素的感知能力。置信度约束校准:引入置信度约束机制,通过对不确定样本的惩罚,优化模型的置信度估计能力。
-
